今天下班途中,在我的 Pocket 列表中看到前些天丢进来的《Python编程中常用的12种基础知识总》一文中的第一个例子:
正则表达式替换。
目标: 将字符串 line 中的 overview.gif 替换成其他字符串
随便分析了一下,感觉不通顺,虽想回家好好分析下,结果掉一坑里去了。文中例子代码丢失一段,导致我想了半天都没想去为啥就要这样匹配,后来机智的我想到肯定是代码不全,Google 了下找到了。在这里鄙视下那些 Ctrl C,Ctrl V 的,万一一个启动脚本里有个 rm -rf / tmp/xxx 那不完蛋了。
cat 03_subtest.py
#!/usr/bin/python import re # line = '<IMG ALIGN="middle" SRC=\'#\'" /span> # 就是这段坑了我 line = '<IMG ALIGN="middle" SRC="overview.gif" BORDER="0" ALT="">' # 将正则表达式编译成Pattern对象 pattern = re.compile(r'(?<=SRC=)"([\w+\.]+)"',re.I) # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None 注意: 其中 \1 是上面()组匹配到的数据,可以通过这样的方式直接引用 str1 = pattern.sub(r'"\1****"',line) print str1 str2 = pattern.sub(r'replace_str_\1',line) print str2 str3 = pattern.sub(r'"testetstset"',line) print str3
来分析上面的正则:
(?<=SRC=)"([\w+\.]+)"
拆分成两段来理解:1、 (?<=SRC=) 2、"([\w+\.]+)"
(?<=SRC=)
(?<=xxx) A positive lookbehind --反向预搜索啥是预搜索?反向应该就是反过来的意思吧?在正则中特殊符号:"^","$","\b"。它们都有一个共同点,那就是:它们本身不匹配任何字符,只是对 "字符串的两头" 或者 "字符之间的缝隙" 附加了一个条件。这个预搜索也是像它们一样是个“附加条件”,不过他们的表示方法更加灵活。(?<=xxx) 所在缝隙(就是要匹配的东西缝隙,这里就是"([\w+\.]+)"匹配到的内容为分割线)的左侧,必须能够匹配上 xxx 这部分的表达式。因为它只是在此作为这个缝隙上附加的条件,所以它并不影响后边的表达式去真正匹配这个缝隙之后的字符。这就类似 "\b",本身不匹配任何字符。"\b" 只是将所在缝隙之前、之后的字符取来进行了一下判断,不会影响后边的表达式来真正的匹配。这里的意思是要匹配的内容前面(左则)为
SRC=才算。就好比"^"要匹配的内容必须是第一个位置一个道理。"([\w+\.]+)"
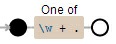
 [\w+\.] 表示 任意一个字母或数字或下划线,也就是 A~Z,a~z,0~9,_,. 中任意一个,
[\w+\.] 表示 任意一个字母或数字或下划线,也就是 A~Z,a~z,0~9,_,. 中任意一个,
这里面的+号我觉得是多余的了。[\w+\.]+ 这里加上加号就是匹配至少1个里面的东西。"([\w+\.]+)"加上() 表示一个组,然后再加上""就可以匹配出 "middle" "overview.gif" "0" 这三个结果了,怎么得到我们想要的"overview.gif"?就要用到前面的 “附加条件了” 附加条件就是 匹配前面有
SRC=
输出结果如下:
javasboy@debianp3 ~/python # python 03_subtest.py <IMG ALIGN="middle" SRC="overview.gif****" BORDER="0" ALT=""> <IMG ALIGN="middle" SRC=replace_str_overview.gif BORDER="0" ALT=""> <IMG ALIGN="middle" SRC="testetstset" BORDER="0" ALT="">
Tips:
- 揭开正则表达式的神秘面纱
- RegExr:
http://gskinner.com/RegExr/ 提供了一个方便的开发工具,可以很方便的测试正则表达式是否有效。- 表达式单元拆分
- 内容实时匹配
- 多模式
- Debuggex:
http://www.debuggex.com/ 提供更为丰富的正则执行流可视化。
下一篇将会转载一篇《Python正则表达式指南》

文章评论